存储格式
磁盘上的存储格式和内存模型其实也有一定的相似之处,我们首先分配一块固定大小的区域用来存放数据,然后利用指针来确定这块区域究竟存放在磁盘上的什么位置。对于我们会广泛使用的指针,实际上就对应着偏移量这样的数字,而分配一块固定大小的区域,就是我们所说的页(Page),这样利用偏移量作为指针指向不同的页,相应的,我们需要非常小心的分配各个页的位置和指针的计算。
在 JavaScript 内存中你可以直接将对象赋值给变量就相当于指针的作用了,但在磁盘上我们的指针都会用一个数字代替,它的意思是在文件中的偏移量 offset。
页布局
因为我们会通过 fs.writeSync 这样的接口来写入,然后通过操作系统抽象为一个文件,那么可以先考虑这个文件的数据布局是怎样的。这里直接抛结论,一般来说除了前面我们提到的页之外,还会分配一块固定大小的头部和尾部,这样可以用来存放一些辅助的信息,比如说数据库的版本啦,Magic header 啦之类的东西。然后剩下的空间就是一个又一个页了:
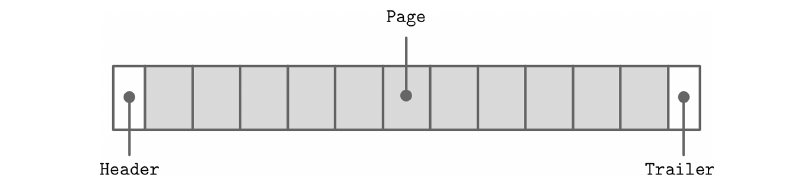
其中每一个页,我们就先拍个脑袋,设定成固定的 4kb 大小,即 4096 个字节。这一个页,也对应着我们 B 树中的一个节点,这样我们的数据库每次都会读取一个页出来放到内存里,然后利用其中存放的指针,再去读取下一个页。
接下来考虑一下指针,实际上指针在这里的意思就是文件内的偏移量,考虑到页都是固定大小的,那我们直接用一个自增的正整数编号就可以了,然后乘以页的大小,就可以算出来它的偏移量。假设这个数字是一个 32 位无符号整数的话,最大值为 4 294 967 295,乘以每个页大小的 4096,可以算出来大概是 16TB 大小,已经超过了很多人日常使用机器的硬盘大小,足够我们使用了,因此对于指针,我们就直接用 32 位,也就是 4 个字节来存储。
接下来我们需要讨论清楚用户需要存储的键值对数据对应的二进制应该如何布局。如果他们都是固定大小的块,那就非常简单了,只需要按照指针、键、值的顺序让他们排排坐就行了,类似下面这样子:

不过这样的设计有几个缺点:
- 往中间插入数据的时候后面的数据都要重新整理位置;
- 数据块的大小是固定的可能造成空间上存在浪费;
- 没办法支持任意可变长度的数据。
为了挑战一下,我们不选择这种比较简单的方式,而是使用一种叫做 Slotted Pages 的技术,我们把一个页分为很多个 slot, 或者叫 cell,他们的大小是不固定的,然后把他们放在页的后面,每次新增的话都是从后往前反着插入的,而页的前面呢,除了一个固定大小的存放元信息的 header 块,从前往后我们放一个一个的指针,这些指针指向了对应的 slot 的位置,记得不要把这里的指针和前面指向页面的指针搞混了,他们是指向这些 slot 的。类似下面这个样子:
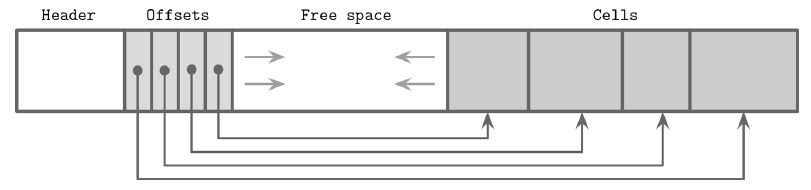
这样呢,数据的插入我们总是让他们按照插入的顺序存放到 cell 里,如果要排序的话,只需要针对前面指针进行排序就行了。删除数据的话,为了避免所有的 cell 都需要重新摆放位置,也不需要真的删除,而是将那一块 cell 标记为删除就行了。这样我们的数据其实永远是从后往前的进行一个顺序写入。如果为了避免浪费想再利用好这些空间,可以把所有的可用的 cell 找出来构造成一个内存中的数组,下次插入的时候从里面找出来合适的写进去。
Cell 布局
单个的 Cell 呢,因为它有的时候存的是用户提交的键或者值,有的时候存放的是指向其他节点的指针,因此我们也需要针对他们设计一个布局好进行区分。这就比较简单了,我们完全也可以像前面设计如何序列化值一样,给他们一个类型的标识符:
const enum CellType {
Pointer, // 存放着指向了其他的子页的指针
KeyValue, // 存放着用户提交的键值对
}
const enum CellType {
Pointer, // 存放着指向了其他的子页的指针
KeyValue, // 存放着用户提交的键值对
}
由于 B 树需要一个用来比较和排序的 key,为了避免误会成用户提交的键值对中的 key ,我们后面管它叫 Seperator key,即分隔键。而用户提交的,就叫做键。 这里我们可以直接就用用户提交的键来作为这个分隔键,为了方便,我们规定键只能使用 ASCII 字符,每个字符都用一个字节来存储。
对于 Pointer 类型,需要有:
- cell 类型
- 分隔键大小
- 子页的指针(其实就是子页的编号)
- 分隔键
对于存放键值对的 KeyValue 类型的 cell,需要有:
- cell 类型
- 分隔键大小(也就是键的大小)
- 值的大小
- 键值对
注意:前面我们只是简单的实现了三种类型的值,分别是 数字,布尔 和 字符串,但实际上键也是应该有类型的,之前的实现默认将其作为了字符串类型处理。我们还是维持这个设计,暂时先不增加更多的类型。
我们的页只有 4kb 的大小,而且本身就没办法把全部的 4kb 都用来存储数据,因此要考虑数据超过了这个页的大小产生了溢出怎么办。通常来说溢出的话也可以通过留下一个指针然后将数据分配到其他页来处理,以 MySQL InnoDB 为例,如果数据特别大的话会将其分散到多个页里,然后每个页记录了前一页和后一页的指针,这样页之间形成一个双向链表串联起来。但为了控制复杂度,我们先不考虑这么多,就强行规定死一个固定的大小。为了方便用一个字节的 8 位正整数就可以表示出他们占用的空间的大小,因此这里规定键和值的大小均不能超过 256 个字节。
你看,设计一个数据库就是有这样无数多的细节要处理,更别提我们已经做了最大程度的简化了,The devil is in the details...
终于,马上我们又可以开始着手写代码了!