介绍
"What I cannot create, I do not understand." – Richard Feynman
一直以来我对数据库的认识只停留在简单的使用上,它的内部实现对我来说就像黑盒一样。
我也阅读了一些数据库相关的书籍和资料,不过大部分都着重于介绍如何去使用数据库。而讲解其内部实现的对我的水平来说往往又太过复杂,直到我看到了这篇文章,不过很可惜这个系列没有完结,并且使用的是我并不熟悉的 C 语言。
但受此启发,我觉得应该自己也动手来实现一个最简单的数据库,以帮助自己理解数据库究竟是怎么工作的。并且我会选择使用 Node.js 来实现,一个是因为这是我最熟悉的工具,另外 JavaScript 也是编程界事实上的 lingua franca,几乎所有人都能看懂。
为了方便,我会使用 TypeScript,不过不用担心,我们只会使用到类型标注或者枚举这样简单又方便的特性,并不会涉及到复杂的泛型和各种类型体操。
我们的目标设定的很小,就是写一个最简单的数据库,但它会覆盖数据库实现里的大部分核心概念,例如:
- 执行语句输入到输入的过程是什么样的?
- 数据以什么格式保存?(在内存和磁盘上)
- 它什么时候从内存移动到磁盘?
- 事务如何工作?
- 如何建立索引,B 树,B+ 树是干啥的?
- 简而言之,数据库到底是怎么工作的?
传统的数据库或者数据存储系统虽然可能有不同的架构,或者底层使用了不同的数据结构,但实际上大体上的流程也是有很多相似的地方:
- 一条执行命令通常需要先交给编译器之类的模块,从一串字符串转变成内存中方便操作的数据结构;
- 再交给类似优化器之类的模块可以生成高效的执行计划;
- 通过利用 B 树这类的数据结构快速定位到磁盘上的位置;
- 通过操作系统接口进行数据的增删改查;
以 SQLite 为例,它主要有下面七个模块组成:
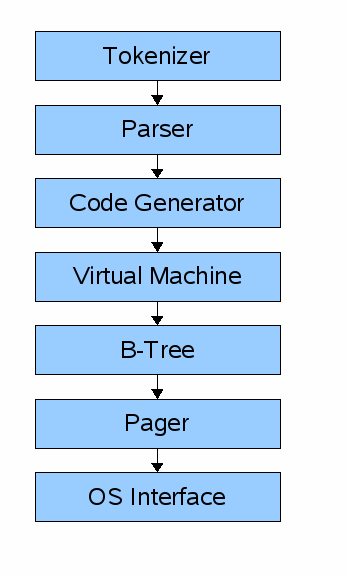
当输入一条 SQL 语句并提交给 SQLite 以后,会依次先交给前端的三个模块进行处理:
- Tokenizer
- Parser
- Code Generator
这样会从输入的字符串,输出 SQLite 的虚拟机字节码(本质上是一个可以在数据库上操作的编译程序)。
后端则包括:
- Virtual Machine
- B-Tree
- Pager
- OS interface
虚拟机将前端生成的字节码作为指令。然后它可以对一个或多个表或索引执行操作,每个表或索引都存储在称为 B 树的数据结构中。
每个 B 树由许多节点组成。每个节点的长度为一页。B-tree 可以通过向 Pager 发出命令从磁盘检索页面或将其保存回磁盘。
TIP
值得一提的是,B 树在英文中一般写作 B-tree,还有一个变体叫 B+ tree,因此有的中文翻译把中间的连字横杠误会成了减号,称呼其为 B 减树,实际上并不存在 B 减树,只有 B 树和 B 加树,他们对应的英文分别是 B-tree (Bee tree) 和 B+ tree (Bee plus tree)。
Pager 接收读取或写入数据页的命令。它负责在数据库文件中的适当偏移处读取/写入。它还将最近访问的页面缓存在内存中,并确定何时需要将这些页面写回磁盘。
OS 接口则是为了支持多个平台和操作系统所作的一层抽象,因为 Node.js 是跨平台的,因此这里我们不用管这个。
在这个系列里,我们关注的重心,主要是在后端的存储引擎部分。很多内容主要参考了下面几本书,感谢和赞美他们: